经过一周时间修复了SteemMention的提醒延时问题
steem-mention·@ety001·
0.000 HBD经过一周时间修复了SteemMention的提醒延时问题
[SteemMention](https://steem-mention.com) 是一个使用邮件接收 Steemit 回复提醒的工具,无需注册,只要有邮箱即可立即使用。 从 [上周发布](https://steemit.com/utopian-io/@ety001/another-mention-tool-for-steem) 到现在,[SteemMention](https://steem-mention.com) 整体运行平稳,不过我在运行的第一天就发现了一个比较严重的问题,就是用户收到提醒的时间会越来越晚。具体问题是怎么导致的呢? 先看一下第一版程序的同步脚本的核心思路图: 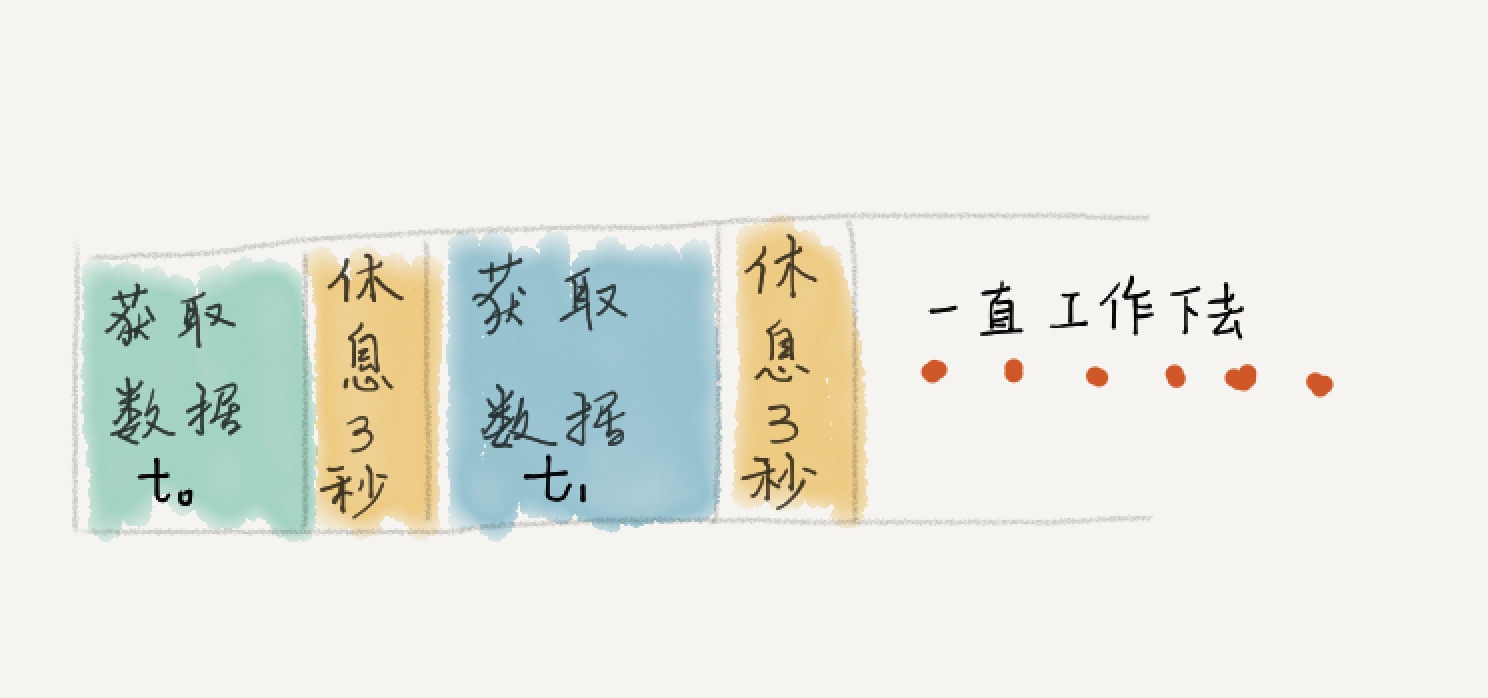 第一版的思路很简单,就是获取数据然后等待3秒,无限循环下去。这里问题出在了:我忽略了获取数据是属于高延时操作,且每次的执行时间是不定的,这就直接导致**每个循环的执行时间远大于3秒**。 用户收到提醒的时间越来越慢,就是因为区块链数据每3秒更新一个区块,而我的同步程序每 (3+t[n]) 秒才拿到一个区块数据,其中 t[n] 是一个远大于1秒且不定的值。 经过一周对 Python 和 Python 中异步多线程的学习,我对程序做了很大的改动,如下图所示: 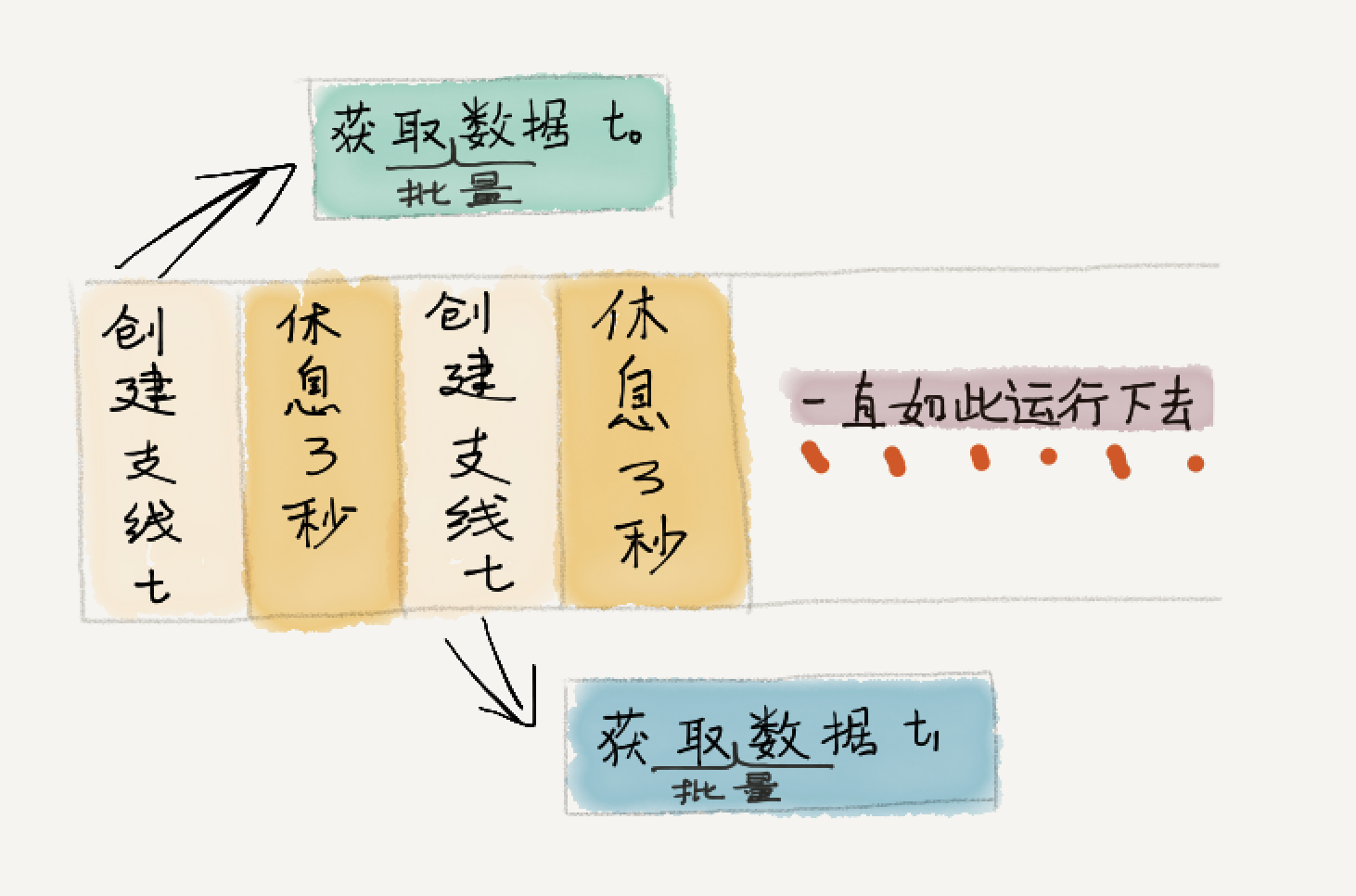 首先,程序使用了异步多线程的概念,其次就是每次获取数据改为了批量获取,即从上次结束的位置到最新位置之间的数据。 这样一来,创建支线任务的时间 t 是一个极小的值,且可以理解为每次操作的耗时是稳定的。同时由于每个支线任务是独立的,并不存在共享资源,主线程也不需要知道支线任务的执行结果,这样就可以让主线程的循环体执行时间稳定在3秒多一点。 另外,每次循环去获取批量数据,则是进一步修正了每个循环的时间在3秒多的问题。 新版本程序已经在**2月5日14点**更新了,目前几个小时的运行来看,效果不错。不过貌似多线程的操作是同步的,而不是异步的,目前完全靠批量获取来保证同步脚本能够跟上区块链数据更新。还需要继续看看 Python 的多线程任务。 --- 感谢你的阅读,我是一个见证人,欢迎通过 [SteemConnect](https://v2.steemconnect.com/sign/account-witness-vote?witness=ety001&approve=1) 来给我投票。 Thank you for reading. I'm a witness. I would really appreciate your witness vote! You can vote by [SteemConnect](https://v2.steemconnect.com/sign/account-witness-vote?witness=ety001&approve=1).  (图片制作于 [Pix](https://pix.domyself.me))
👍 ety001, ew-and-patterns, yoongeun, cha0s0000, geass, shengjian, moobear, shentrading, foodielifestyle, serenazz, dailyfortune, happyukgo, superbing, justyy, dailystats, dailychina, msp-lovebot, greatabel, xiaoshancun, peaceandlove, fanso, lsuny, wlcpu, liuye, cnbuddy, minnowsupport, huangzuomin, tvb, yjcps, idx, abit, ethanlee,