A Much Deeper Look into Duplicate Comments on HIVE
hive-133987·@holoz0r·
0.000 HBDA Much Deeper Look into Duplicate Comments on HIVE
This work is a follow up to recently published investigations: - [Text analytics reveal thirty two percent of comments are not unique and add no value to discussion](https://peakd.com/hive-133987/@holoz0r/text-analytics-reveal-thirty-two-percent-of-comments-on-hive-are-not-unique-and-at-least-ten-percent-add-no-value-to-discussion) - [Further analytics regarding comments on HIVE](https://peakd.com/hive-133987/@holoz0r/further-analytics-regarding-comments-on-hive) This post examines data from January 2025 through to the conclusion of April 2025, to enable broader analysis of the type of comments published on the platform. The data set examined in this post has 1,758,556 rows. This covers 118 days of full data, representing an average of 14,903 comments a day. Through this post, I will focus on a few interesting topics, as I refine my investigations into a deeper analysis leading down to the comment quality. Before we look at comment quality, I want to revisit the comment "uniqueness" path. <h2>Comment Uniqueness / Duplicates</h2><br/>**TLDR: 27.1% (476,937) of comments are not unique.** Of the rows examined, 1,281,619 contain unique comments, which means that we are left with 476,937 comments which are repeated. Some are repeated by the same user, while others are comments left by different users, that contain the same comments. There are 44,876 rows of duplicate comments after they are grouped into the format: | Comment Text | Frequency | Unique Authors | Percentage | Word Count | **What causes not unique comments?** Examination of the duplicate rows reveals the following (and a lot of this is not new information) Note that all percentages expressed here are the percentage of the non unique comments, not the total percentage of comments on the chain for the period: <center>**Notable Curation Projects leaving duplicate comments**</center> - Curation Projects Leaving a Comment with the "Felt" Sentiment token making up some 16.4% (7401) of the period's non unique comments - Splinterboost upvoting posts about Splinterlands and leaving a comment, 13.4% (6039) of duplicate comments for a 12% upvote, (3.2%, 1478 comments) for 5% upvotes and (3%, 1327 comments) for 15% upvotes. There's probably more. By my count, this makes **splinterboost** the most prolific in publishing duplicate comments to hive. - Pandex (2333 comments, by 1 user, for 5.19%) <center>**Bot Calls for Tokens**</center> Bot Calls, including calls bbh (6651 comments, by 1223 users) 14.82% lolz (5252 comments by 129 users) 11.7% hiqvote (3145 comments by 88 users) 7% (beer 2556 comments by 73 users) 5.69% (nice?) lady (1939 comments by 2 users) 4.32% pizza (1855 comments by 102 users) 4.13% hbit (1418 comments by 91 users) 3.16% And these are only the top 25 duplicate comments being examined! 22,816 comments are <em>ONLY</em> calls to these bots, without any further remark. <center>**Common Phrases**</center> Humans say the same thing to humans. The fifth most repeated, non-unique comment is "thank you", with it being made 5,027 times by 919 users, for a total of 11% of the duplicate comments. Variations such as "thanks" appear 2970 times, by 700 users, for 6.6%, then we get "thank you!" 2563 times by 523 enthusiastic users. We say thank you a lot, here's some examples, and their incidence: | Comment | Frequency | Number of Users | % Non Unique | Word Count | |------------------------|-----------|-----------------|--------------|------------| | thanks | 2970 | 700 | 6.618237 | 1 | | thank you! | 2563 | 523 | 5.711293 | 2 | | thanks! | 2151 | 338 | 4.793208 | 1 | | thank you. | 1587 | 311 | 3.536411 | 2 | | thank you so much | 1124 | 382 | 2.50468 | 4 | | you're welcome | 1083 | 141 | 2.413317 | 2 | | gracias | 917 | 253 | 2.043409 | 1 | | thank you so much! | 601 | 182 | 1.339246 | 4 | | thank you so much. | 470 | 157 | 1.04733 | 4 | | welcome | 450 | 68 | 1.002763 | 1 | | you are always welcome | 416 | 8 | 0.926999 | 4 | | muchas gracias | 412 | 159 | 0.918085 | 2 | | your welcome | 198 | 30 | 0.441216 | 2 | | thank | 64 | 31 | 0.142615 | 1 | | thank youu | 25 | 18 | 0.055709 | 2 | | thank you) | 11 | 5 | 0.024512 | 2 | | graciasss | 9 | 7 | 0.020055 | 1 | | thank you, | 9 | 5 | 0.020055 | 2 | | graciass | 6 | 5 | 0.01337 | 1 | | thankssss | 5 | 5 | 0.011142 | 1 | | graciassss | 4 | 4 | 0.008913 | 1 | | thanksss | 4 | 4 | 0.008913 | 1 | | gracia | 3 | 3 | 0.006685 | 1 | | thank you so much, | 2 | 2 | 0.004457 | 4 | There are probably more variations that my regex didn't catch, but the totals here are 15,084 comments, by 3,341 users. **Now I'm interested in commonly appearing terms in the comments:** First, let's start with some words: | Duplicate Comment Contains | Appears in How Many Comments | |----------------------------|--------------------------------| | hive | 168093 | | thank | 92066 | | vote | 74882 | | HP | 46458 | | delegate | 30425 | | curate | 27366 | | witness | 16147 | | delegation | 12540 | | splinterlands | 10474 | | splinterboost | 10435 | | shit | 9200 | | fuck | 1157 | | nice post | 157 | 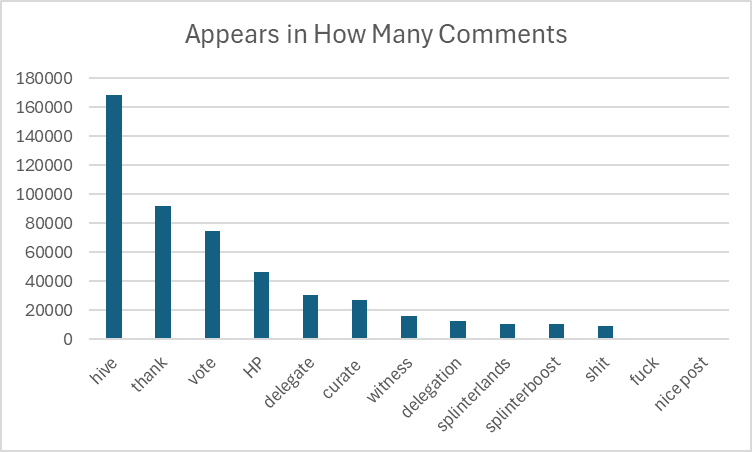 Next, lets look at some web activity: | Duplicate Comment Contains | Appears in How Many Comments | |-------------------------------------|--------------------------------| | "http" (Contains some sort of link) | 188203 | | ".png" (Contains a PNG) | 83684 | | ".gif" (Contains a GIF) | 33247 | | ".jpg" (Contains a JPG) | 26893 | | "youtube" (mentions YouTube) | 4985 | | "twitter" (mentions twitter) | 4603 | | ".webp" (Contains a webp) | 1331 | | "Reddit" (mentons reddit) | 524 | | "facebook" (mentions facebook) | 368 | | ".jpeg" (Contains a JPEG) | 286 | | ChatGPT | 13 | | "github" (mentions github) | 7 | 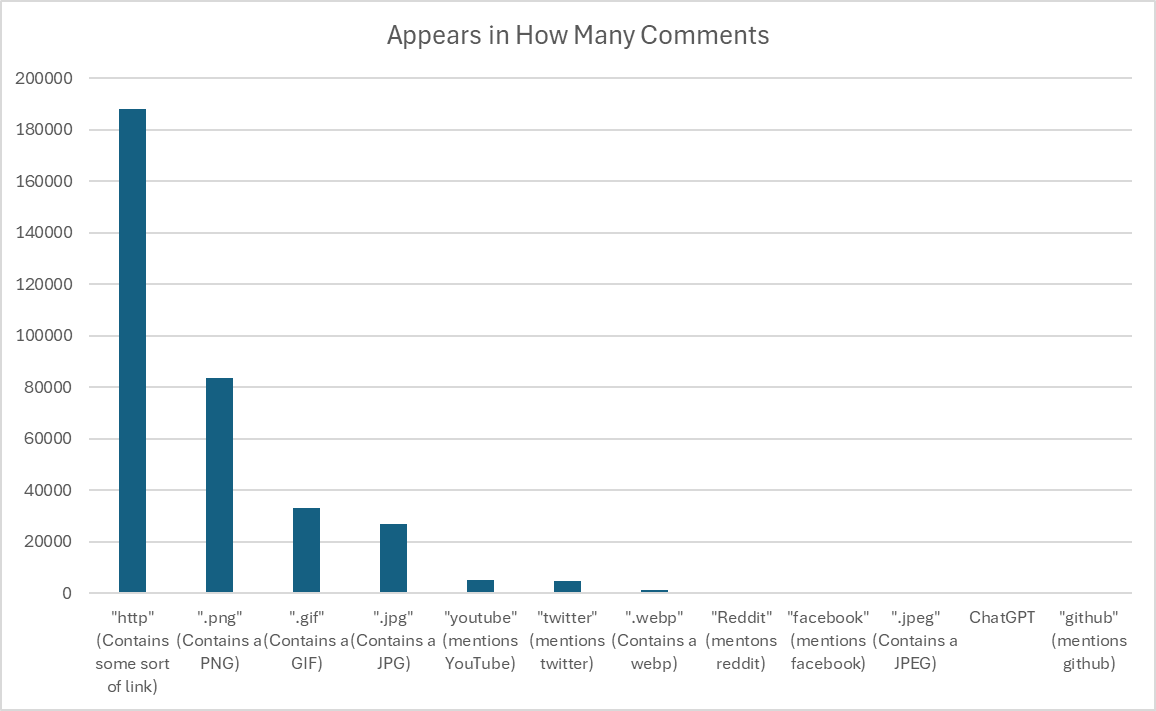 The next part of my study, which I'll do at some point in the future, will focus on "Ranking" user comments in terms of complexity. This will take into account length, word count, sentence counts, and comment depth. I will come up with some sort of scoring algo, and see who comes out on the top. As that will be based on a "user" dimension, we'll finally find out who swore the most in the study period ;)
👍 iumac03, freebornsociety, maxmaka, bearone, soufianechakrouf, irregular-n, cmmndrbawang, monsterguru, jarvie, strega.azure, minismallholding, celinavisaez, teamaustralia, izzydawn, realtreebivvy, life-relearnt, davidtron, backinblackdevil, sbi3, shauner, sbi-tokens, noloafing, sneakyninja, thedailysneak, babysavage, ravensavage, michael561, emsenn0, splinterlandshq, c0ff33a, rehan.blog, braaiboy.spt, blue.panda, whiterosecoffee, the.lazy.panda, portugalcoin, teamuksupport, fazendadolobo, cryptosneeze, tommys.shop, gamersclassified, stayoutoftherz, builderofcastles, kenny-crane, leighscotford, vvodjiu, teamvn, beatminister, russia-btc, steevc, marsupia, soundminds, jacobtothe, pokerarema, jagged, vladalexan, harbiter, mattclarke, damour, borgheseglass, urun, vatman,