빅 데이터 분석하기 #10 - Hadoop/Spark 데이터 처리 방식
kr·@jingdol·
0.000 HBD빅 데이터 분석하기 #10 - Hadoop/Spark 데이터 처리 방식
https://steemitimages.com/DQmUTTpdP7bu9qCgb3GhFjmJWbLkS3yJ3U8xFTTnGRRUmaD/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA%202017-08-27%20%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE%206.19.27.png 안녕하세요 @jingdol 입니다^^ kr-science 태그가 활발해 졌으면 하는 마음에 부족하지만 "빅 데이터" 관련글을 시간나는 대로 올려볼까 합니다. 스팀잇 유저분들이 다양한 background를 가지고 게시다는걸 고려해서 최대한 쉽게 풀어보도록 하겠습니다. 지난 글에서 Hadoop에 대해서 이야기를 했었는데요, 하둡(hadoop)과 Spark은 빅 데이터 분석하시는 분들이라면 자주 듣게 되는 용어들입니다. 오늘은 이 두가지에 대해서 간략하게 이야기 해 볼까 합니다. # Hadoop의 데이터 처리 - DISK 기반 데이터 처리 방식 당연한 얘기지만, 디스크에서 데이터를 처리 하는 것보다 메모리에서 처리하는게 훨씬 빠릅니다. 그 이유는 데이터 처리 (transformation/연산) 시간 외에도 파일을 읽고 쓰고(Disk IO)하는 시간이 있기 때문 인데요. 파일을 읽고 쓰는 하는 시간이 컴퓨터에서는 크기 때문에, 많은 데이터를 빠르게 처리 해야 할 경우에는 이 구조가 문제가 됩니다. 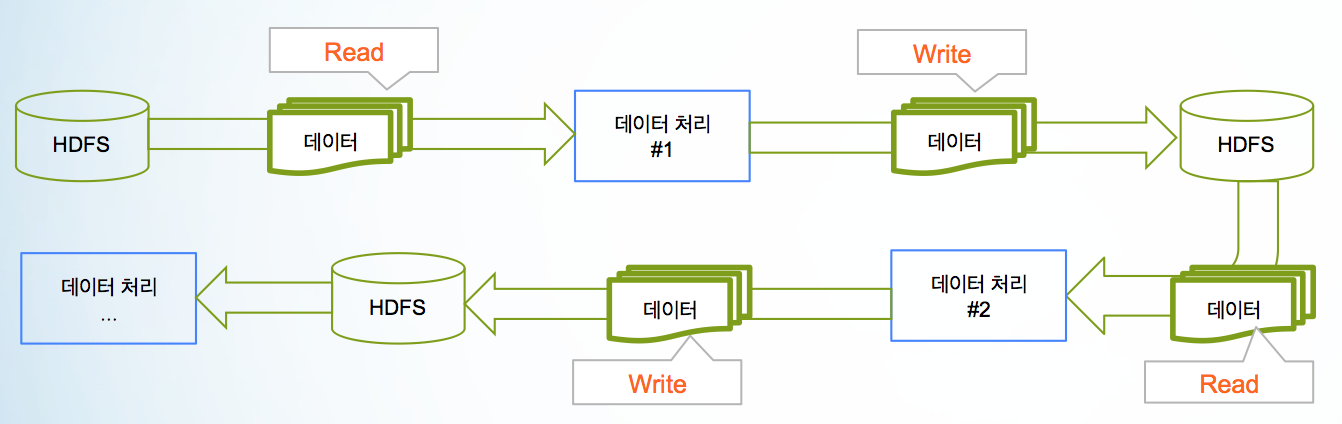 # Apache Spark - 인메모리(In-memory) 기반 데이터 처리 방식 Apache Spark은 대규모 데이터를 빠르게 처리하게 해주는 분산 클러스터 컴퓨팅 프레임워크(Distributed Cluster Computing Framework)입니다 - 하둡 Map-Reduce보다 100배 이상 빠름. Java, Scala, Python 그리고 R을 기반으로 동작하며 스트리밍 (Spark Streaming), SQL, 기계 학습 (MLLib) 및 그래프 처리 모듈이 내장 되어있어 빅 데이터를 batch/streaming 기반으로 처리 할때 유용하게 쓰입니다. # Spark 기반 Batch/Streaming 데이터 처리 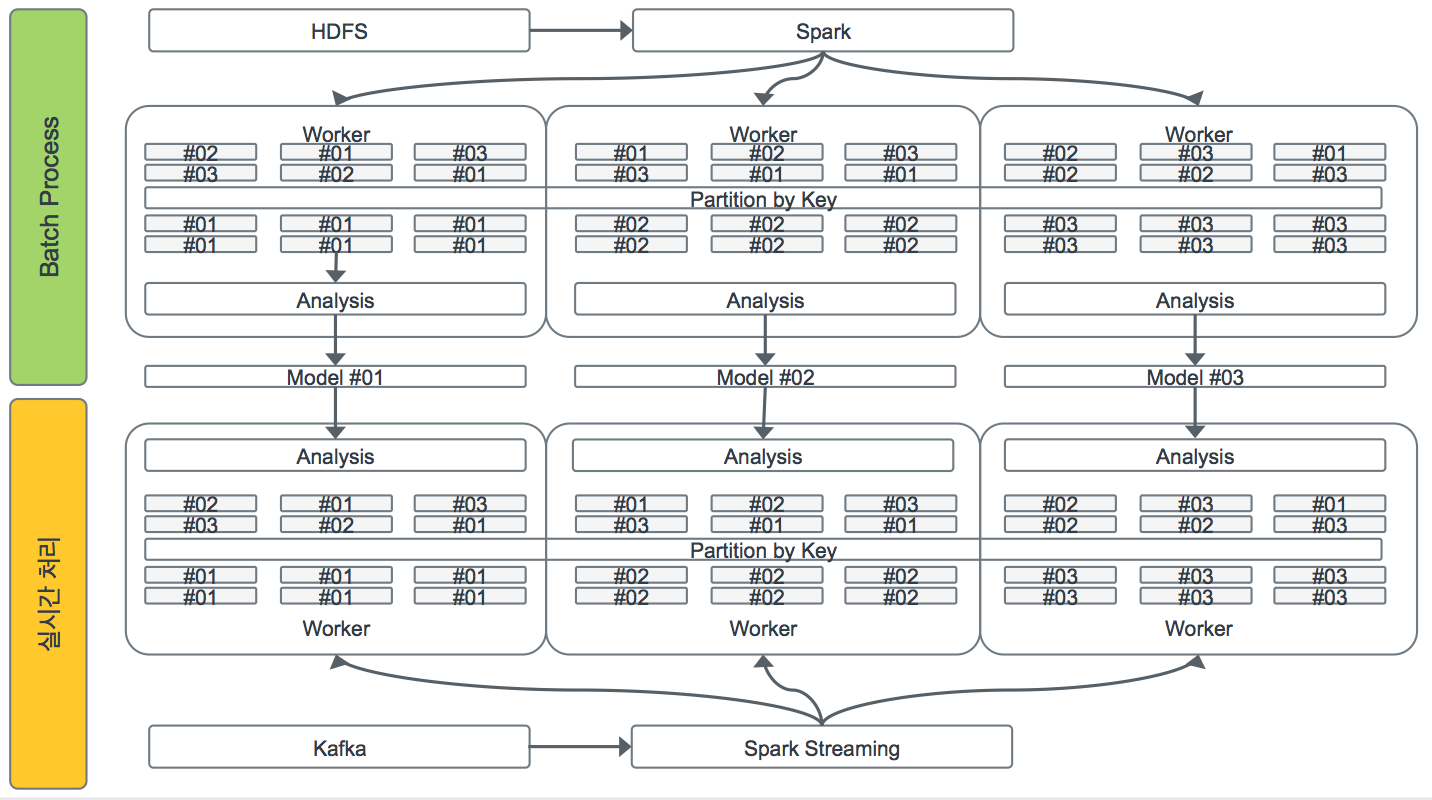 Batch process - 주기적으로 많은 데이터를 처리 (예: 하루 한번) Streaming process - 실시간으로 데이터를 처리 Batch 기반의 데이터 처리는 수집된 많은 과거 데이터를 가지고 분석/모델을 만들때 사용됩니다. Streaming process는 현재 수집되고 있는 데이터에 batch process에서 만든 모델을 적용해 볼때 사용됩니다. # 목록 "빅데이터 분석하기 #1 - 빅데이터 개요" https://steemit.com/kr-scientist/@jingdol/1 "빅데이터 분석하기 #2 - R 소개" https://steemit.com/kr-science/@jingdol/2-r "빅 데이터 분석하기 #3 - 우리는 왜 빅 데이터 기술이 필요 한가?" https://steemit.com/kr-science/@jingdol/3 "빅 데이터 분석하기 #4 - 세상을 바꾸는 빅 데이터 기술" https://steemit.com/kr/@jingdol/4 "빅 데이터 분석하기 #5 - 필요한 기술? 데이터 엔지니어 / 데이터 분석가" https://steemit.com/kr/@jingdol/5 "빅 데이터 분석하기 #6 - 필요한 기술? 데이터 엔지니어 / 데이터 분석가 (Part 2)" https://steemit.com/kr/@jingdol/6-part-2 "빅 데이터 분석하기 #7 - 외로운 데이터 분석가" https://steemit.com/kr/@jingdol/7 "빅 데이터 분석하기 #8 - 왜? 빅 데이터가 생겨 났을까? https://steemit.com/kr/@jingdol/ft5pv-7 "빅 데이터 분석하기 #9 - 하둡과 하둡 관련기술 (Apache-Hadoop Distributed Processing Framework)" https://steemit.com/kr/@jingdol/9-apache-hadoop-distributed-processing-framework