[ESP-ENG] Títulos y enlaces de threatpost || Get titles and links from threatpost
hive-148441·@pynomiems·
0.000 HBD[ESP-ENG] Títulos y enlaces de threatpost || Get titles and links from threatpost
<center>
<center><sub>Imagen diseñada con <a href="https://snappa.com/app/">snappa</a> || Image designed with <a href="https://snappa.com/app/">snappa</a></sub>
</center>
</center>
<div class="text-justify">
Saludos hivers. He creado un script en Python para obtener los títulos y enlaces de otro sitio web centrado en la ciberseguridad, se trata de https://threatpost.com/ un sitio de noticias que abarca temas relacionados con la seguridad informática, es un sitio web con una interfaz cómoda y simple de usar. Además, tiene una sección de seminarios web el cual le he dado una pequeña revisión y me parece muy didáctica para comprender el mundo de la vulnerabilidad informática y que debemos hacer para tener un sistema más seguro contra hackers.
En fin, les dejo el script y resultados para que lo puedan usar y comprender su funcionamiento. Hasta la próxima entrega, espero que esta publicación les resulte agradable.
**Este script fue ejecutado con Python 3.9.2 en el sistema operativo Debian Bullseye**.
<blockquote>
Greetings hivers. I have created a Python script to get the titles and links of another website focused on cybersecurity, it is https://threatpost.com/ a news site that covers topics related to computer security, it is a website with a comfortable and simple interface to use. In addition, it has a section of webinars which I have given a little review and I find it very educational to understand the world of computer vulnerability and what we must do to have a more secure system against hackers.
Anyway, I leave you the script and results so you can use it and understand how it works. Until the next installment, I hope you enjoy this publication.
**This script was executed with Python 3.9.2 on Debian Bullseye operating system.**
</blockquote>
<div class="text-justify">
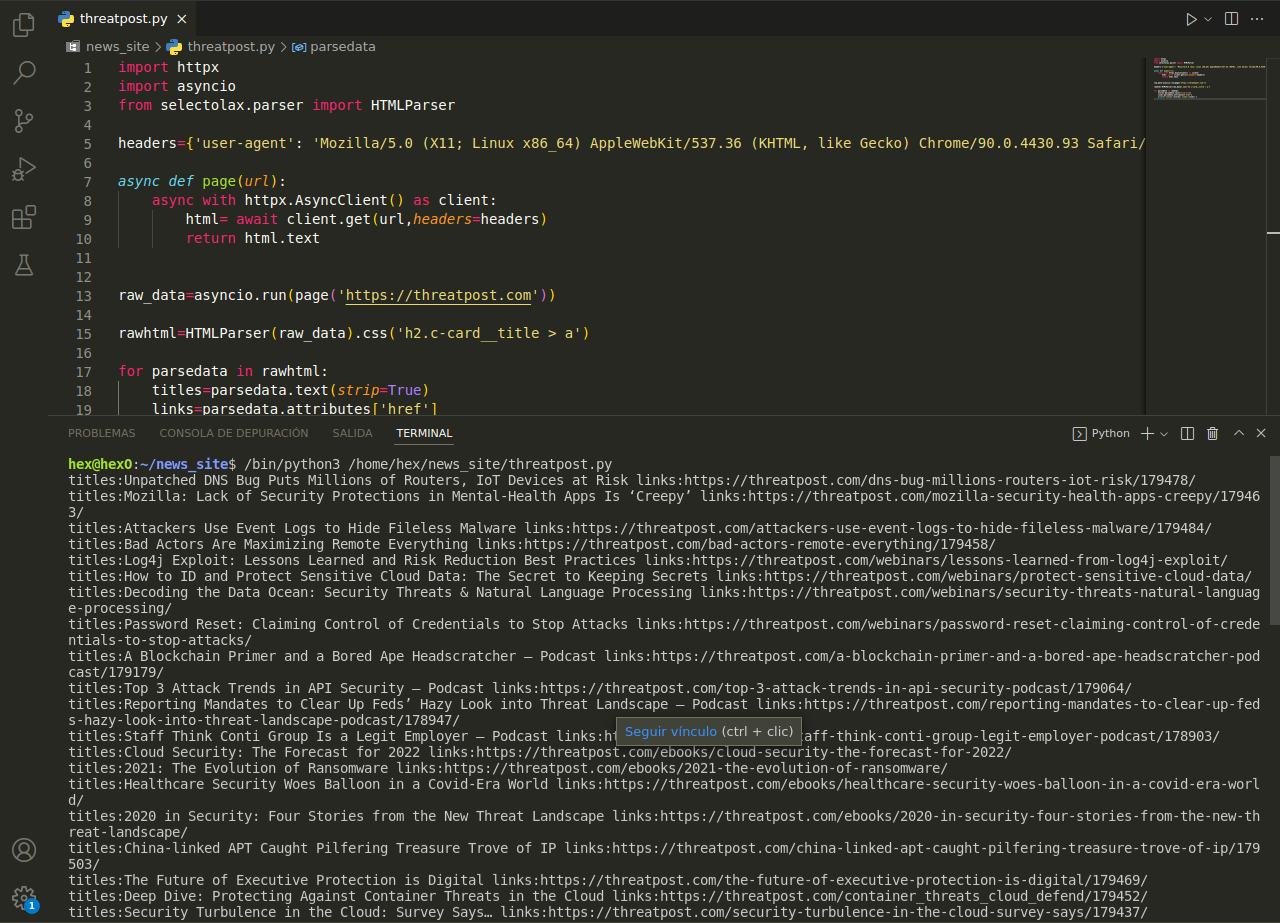
<pre>
import httpx
import asyncio
from selectolax.parser import HTMLParser
headers={'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36 RuxitSynthetic/1.0 v1934675838 t2795071688239799734 athfa3c3975 altpub cvcv=2 smf=0'}
async def page(url):
async with httpx.AsyncClient() as client:
html= await client.get(url,headers=headers)
return html.text
raw_data=asyncio.run(page('https://threatpost.com'))
rawhtml=HTMLParser(raw_data).css('h2.c-card__title > a')
for parsedata in rawhtml:
titles=parsedata.text(strip=True)
links=parsedata.attributes['href']
print(f'titles:{titles} links:{links}')
</pre>
</div>
<center>
</center>
---
<center>
## Text translated by <a href="https://www.deepl.com/es/translator">DeepL</a>
</center>